

Data-driven computational pipelines
Nextflow enables scalable and reproducible scientific workflows using software containers. It allows the adaptation of pipelines written in the most common scripting languages.
Its fluent DSL simplifies the implementation and the deployment of complex parallel and reactive workflows on clouds and clusters.

Join us for the latest developments and innovations from the Nextflow world!
With training, a hackathon and talks from pioneers in the field, the Nextflow Summits are essential events for anyone using Nextflow.
Register now
Just download and play with it. No installation is required.
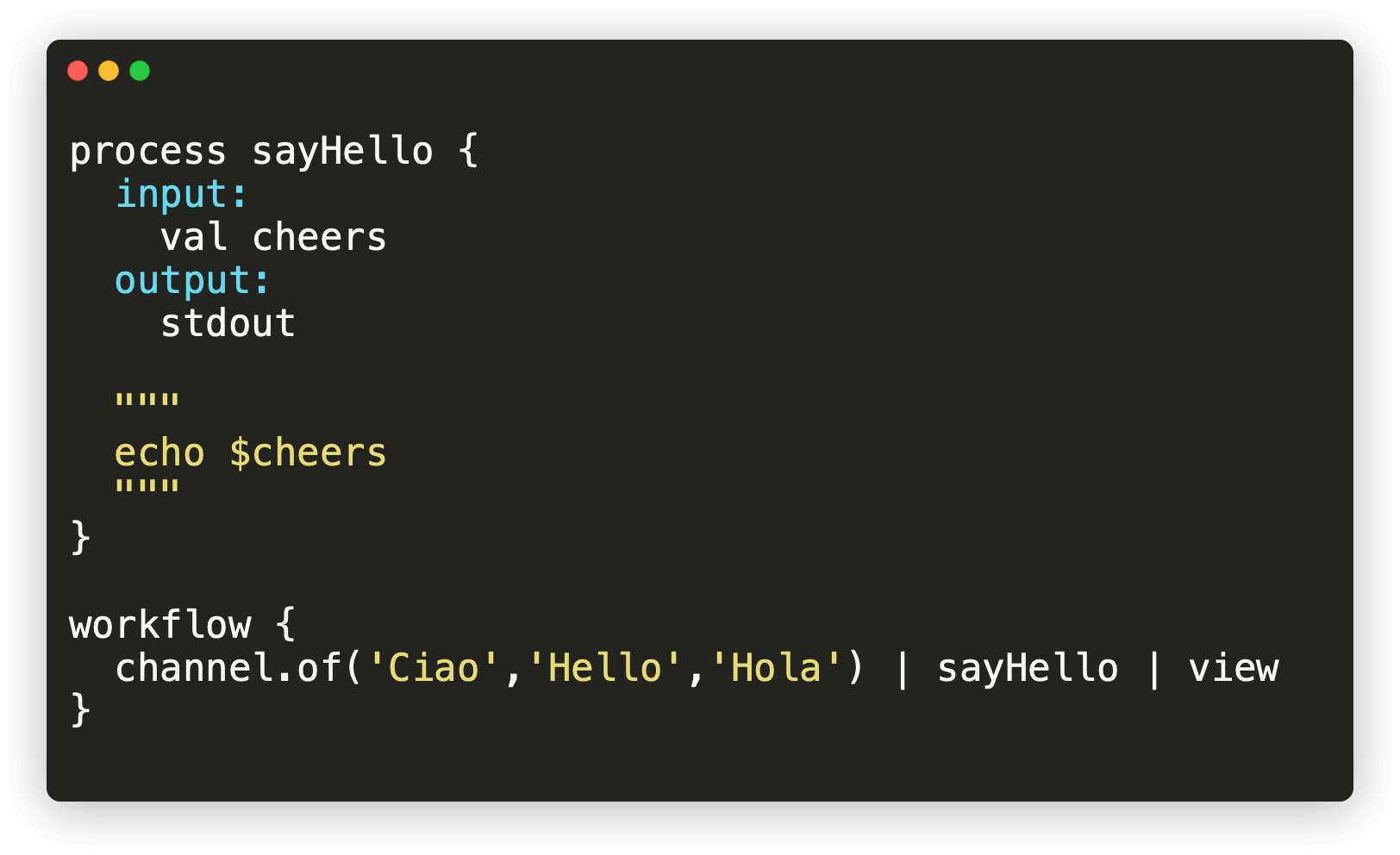
Are you a Python geek or a Perl hacker?
You can start fast with it.
Lightweight processes with message passing, no shared memory
Develop on your laptop, run in the grid or scale-out in the cloud with no changes.
Nextflow is built around the idea that Linux is the lingua franca of data science.
Nextflow allows you to write a computational pipeline by making it simpler to put together many different tasks.
You may reuse your existing scripts and tools and you don't need to learn a new language or API to start using it.
Nextflow supports Docker and Singularity containers technology.
This, along with the integration of the GitHub code sharing platform, allows you to write self-contained pipelines, manage versions and to rapidly reproduce any former configuration.
Nextflow provides an abstraction layer between your pipeline's logic and the execution layer, so that it can be executed on multiple platforms without it changing.
It provides out of the box executors for GridEngine, SLURM, LSF, PBS, Moab and HTCondor batch schedulers and for Kubernetes, Amazon AWS, Google Cloud and Microsoft Azure platforms.
Nextflow is based on the dataflow programming model which greatly simplifies writing complex distributed pipelines.
Parallelisation is implicitly defined by the processes input and output declarations. The resulting applications are inherently parallel and can scale-up or scale-out, transparently, without having to adapt to a specific platform architecture.
All the intermediate results produced during the pipeline execution are automatically tracked.
This allows you to resume its execution, from the last successfully executed step, no matter what the reason was for it stopping.
Nextflow extends the Unix pipes model with a fluent DSL, allowing you to handle complex stream interactions easily.
It promotes a programming approach, based on functional composition, that results in resilient and easily reproducible pipelines.
It can be used on any POSIX compatible system (Linux, OS X, etc).
Simply follow these three steps.
Java 11 or later is required
java -version Try a simple demo
./nextflow run hello